Some people have succeeded in teaching a machine (computer) how to judge human beauty to a reasonable extent. This can only be possible if most people share a similar sense of beauty and the computer picks up the pattern. I will be addressing the shortcomings of a study in this regard.
Eisenthal et al.(1, pdf) showed that a learning computer could be made to teach itself what humans find physically attractive in women’s faces. The best correlation between the human ratings and the computer’s after it picked up patterns in human judgment was 0.65. The authors largely relied on the faces of some white women photographed by Akira Gomi, and showed that the judges in their study rated the attractiveness of these women similarly to how judges in other cultures had rated them. This dataset has been addressed previously.
The minor shortcomings of the article should be cleared first. The authors described correlates of beauty in women such as a high forehead and a smaller nose as neonate, but this is incorrect terminology; see the comment on neoteny in a previous article. The authors also mentioned high cheekbones as a correlate of beauty in women, but like many others they confounded more sideways prominent cheekbones with higher cheekbones (cheekbones that are vertically placed higher on the face). Higher cheekbones are associated with greater masculinization.
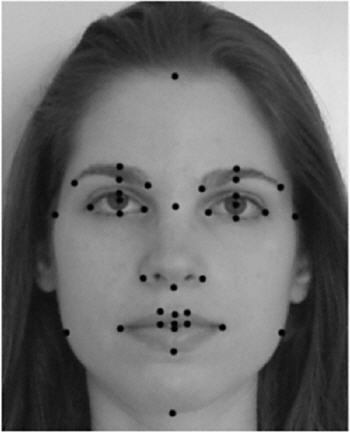
The authors used photos of the women’s faces and measured distances between various points shown below.
The authors described a distinction between facial features (such a nose width, lip thickness, distance between eyes, etc.) and configurational information (how the features fit together). The size of various facial features can be measured by the distances between various points shown in Fig. 1.
Fig. 1. Landmarks used to assess size of facial features.
The information regarding how it all fits together is contained in the totality of the pixels data in each photo. A pixel is a picture element that defines the properties of the image at a given point. There are problems with pixels-based data. A modest 600 X 600 pixels image has 360,000 pixels in it, and not all of them are relevant. Some of them capture information relating to shades associated with light being scattered by the 3D face, which are confounded with different skin tones related to, say, blotches, spots, etc.
The authors were apparently not aware of geometric morphometrics, whereby measuring the coordinates of the points shown in Fig. 1 for each image would simultaneously provide information about facial features and how these features fit together. So the only remaining issue would be to capture information regarding skin texture. An example is shown below. Crow’s feet and smile lines are among the first wrinkles to appear on the face, and instead of scanning the whole face, aiming for these areas would be a good enough approximation of the state of wrinkling of the face. On the other hand, the authors limited their stimuli to young adult women because they didn't want to add the confound of wrinkles.
Fig. 2. Crow’s feet and smile lines are associated with aging and reduced attractiveness. The region around the eye in the right image may have been digitally edited.
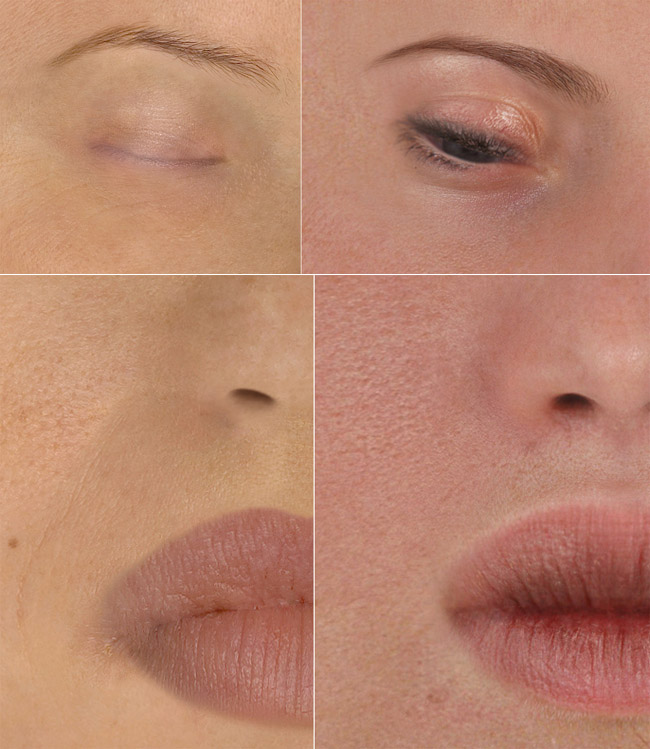
Skin blotchiness/uneven tone is another correlate of attractiveness, and this will have to be assessed, too, but as far as a beauty pageant goes, the contestants will be young adults and naturally selected to have even skin tone. Hence, the problem of a machine-based judgment of beauty in a beauty pageant is much simpler: use geometric morphometrics to simultaneously assess the size of various facial features and how they fit together.
Otherwise, just look at the trouble that Eisenthal et al. had to go through to handle their pixels data. They had to start with a statistical tool know as principal components analysis to capture the variation in the pixels data across all faces in terms of a few independent components. To use this tool, they had to first align the faces by equalizing the distance between the eyes, which distorts size information, and they further aligned the images at the center of the mouth, now distorting the shape information (length-breadth ratio), and subsequently had to adjust for this operation.
Fig. 3. shows what alignment did.
Fig. 3. The first column shows faces that appear without alignment. The middle column shows faces that appear after each face is adjusted to have the same distance between the eyes. The last column shows the result of also aligning faces with respect to the center of the mouth. So the alignment clarifies the features, but it distorts shape.

Fig. 4 shows what the first few principal components corresponded to, shown from first row downward.
Fig. 4. The first row shows that the first principal component, explaining the largest proportion of the variation in the dataset, provided information about rough outline of the face: overall face shape and its delineation from surrounding hair. Subsequent principal components distinguished the finer aspects of facial features.

Fig. 5 shows that the principal components associated with delineating finer aspects of facial features rather than gross face shape best correponded to attractiveness ratings by humans.
Fig. 5. Attractiveness ratings by humans were more strongly associated with finer aspects of facial features rather than gross face shape.

The authors then assessed how well can a computer learn to distinguish what most humans classified as in the top 25% of attractiveness and the bottom 25% of attractiveness. They did this for both types of evaluation, the feature-based measurements and the pixels information. The best learning algorithm correctly classified 75 – 85% of the images. The machine’s assignment of attractiveness ratings achieved a best correlation of about 0.4 with that of humans using the pixels-based information and about 0.6 using the features-based information. The correlation of attractiveness ratings on the part of the computer between the two methods was 0.3 – 0.35. When the data from both the pixels-based information and the features-based information were combined, there was a 10% improvement in the correlation with human ratings (0.65).
The authors had 92 faces in the main dataset, and showed that the computer’s ratings of the faces’ attractiveness improved with exposure to more faces and their ratings by humans without a tendency to level off as the number of faces approached 90, i.e., if there were more faces in the dataset, the computer’s judgment would agree even better with that of the humans’.
The study also showed that average faces were not the most attractive. Again, some correlates of beauty correspond to deviation from the average.
Since computer learning based on the features-based information corresponded to closer agreement with humans’ ratings, it should be obvious that using geometric morphometrics would do a much better job. For beauty pageants there would be no need to bother with the pixels-based information.
The message of this study is that there are obviously some patterns underlying what most people aesthetically prefer in the facial appearance of women or else a computer would not pick it up.
References
- Eisenthal, Y., Dror, G., and Ruppin, E., Facial attractiveness: beauty and the machine, Neural Comput, 18, 119 (2006).
Comments
If a machine is measuring beauty, it would need some sort of measurement scale. I have heard two proposed: the millihelen scale and the beer goddess scale.
The millihelen scale is based on the myth of Helen of Troy, who had the face that launched a thousand ships. A woman who had a face of sufficient beauty to launch one ship, would rate 1 on the millihelen scale.
The beer goddess scale is based on the Syrian goddess of beer. Apparently she was an ordinary looking woman, who after a few beer, would look like a goddess. The beer goddess scale rating is how many beers you would have to drink before a woman would look like a goddess.